Stable Diffusion Chain
Stable Diffusion是一种潜在的文本到图像扩散模型,能够通过文本输入的情况下生成逼真的图像,培养自主自由来产生令人难以置信的图像,使数十亿人能够在几秒钟内创造令人惊叹的艺术。

我们可以做什么
基于潜扩散模型的高分辨率图像合成

文本到图像的模型

让一切成为可能
通过文本输入创建图像
操作简单
stablediffusionweb.com是一个易于使用的界面,用于创建图像可使用最近发布的Stable Diffusion图像生成模型。

高质量图像
可以在几秒钟内创建任何你能想象到的高质量图像-只需输入文本提示并点击生成。

支持GPU和快速生成
非常适合通过模型快速运行一个句子,并快速获得结果。

代币
CtTGa7CUDZAzFyQpSxQvSGJEwjKrThJfhREzmoRL3T3e
已复制
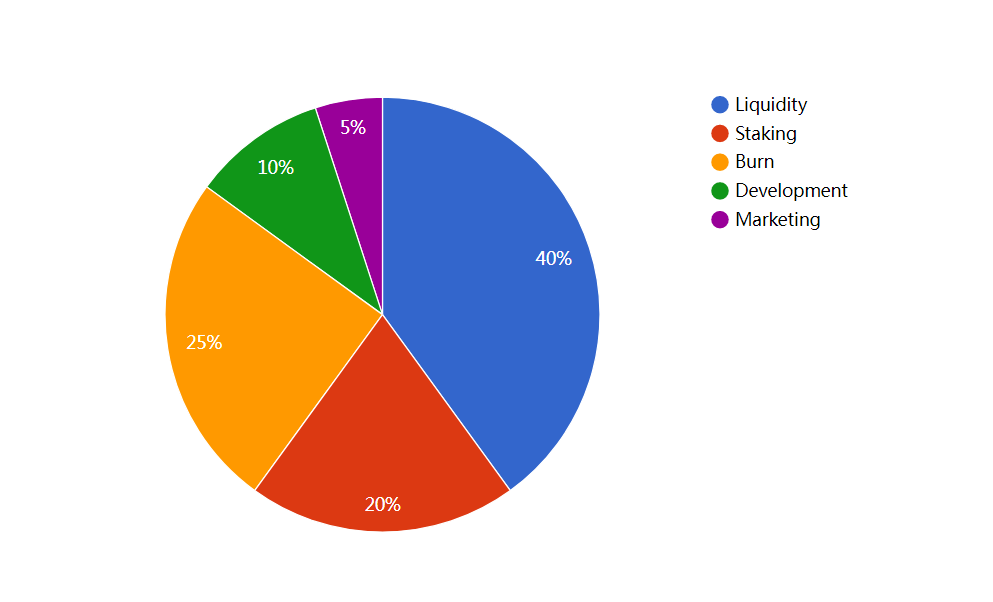
代币质押
即将开始...
🔴 钱包状态: 未连接
Transaction Confirmation
预期收益:
>1999%
常见问题
如果你找不到你想要的问题,给我们的支持团队发电子邮件,我们会不定时的回复。
Stable Diffusion模型的训练对象是什么?
Stable Diffusion的底层数据集是LAION 5b https://laion.ai/blog/laion-5b/的2b英语标签子集,这是由德国慈善机构LAION创建的互联网的通用抓取。
什么样的GPU能够运行Stable Diffusion,在什么设置下?
大多数NVidia和AMD的GPU,6GB以上。
什么是扩散模型?
生成式模型是一类机器学习模型,可以根据训练数据生成新的数据。
使用Stable Diffusion生成图像的版权是什么?
人工智能生成图像和版权的领域很复杂,并且因司法管辖区而异。
艺术家可以选择加入或退出,将他们的作品纳入培训数据吗?
LAION 5b模型数据没有选择加入或退出。它旨在成为互联网语言到图像连接的通用形式。
我们能期待更多的功能吗?
绝对的,我们正在努力。
Copyright © 2023 Stable Diffusion Chain